This is a read-only mirror of pymolwiki.org
Difference between revisions of "Align"
(PYMOL API) |
|||
| Line 62: | Line 62: | ||
===SEE ALSO=== | ===SEE ALSO=== | ||
| − | [[Cmd fit|fit]], [[Cmd rms|rms]], [[Cmd rms_cur|rms_cur]], [[Cmd intra_rms|intra_rms]], [[Cmd intra_rms_cur|intra_rms_cur]], [[Cmd pair_fit|pair_fit]], [[Cmd intra_fit|intra_fit]], [[Kabsch]], [[Cealign]]. | + | [[Cmd fit|fit]], [[Cmd rms|rms]], [[Cmd rms_cur|rms_cur]], [[Cmd intra_rms|intra_rms]], [[Cmd intra_rms_cur|intra_rms_cur]], [[Cmd pair_fit|pair_fit]], [[Cmd intra_fit|intra_fit]], [[Kabsch]], [[Cealign]], [[Color_by_conservation]], [[tmalign]], [[Extra_fit]], [http://pldserver1.biochem.queensu.ca/~rlc/work/pymol/ align_all.py and super_all.py]. |
[[Category:Commands|Align]] | [[Category:Commands|Align]] | ||
[[Category:Structure_Alignment|Align]] | [[Category:Structure_Alignment|Align]] | ||
Revision as of 14:19, 15 January 2012
align performs a sequence alignment followed by a structural alignment, and then carrys out zero or more cycles of refinement in order to reject structural outliers found during the fit. For comparing proteins with lower sequence identity, an alignment program like, Cealign might be a better choice.
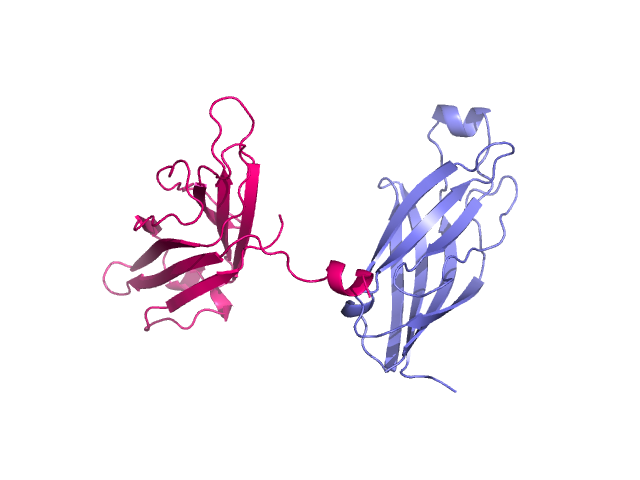
Two unaligned proteins
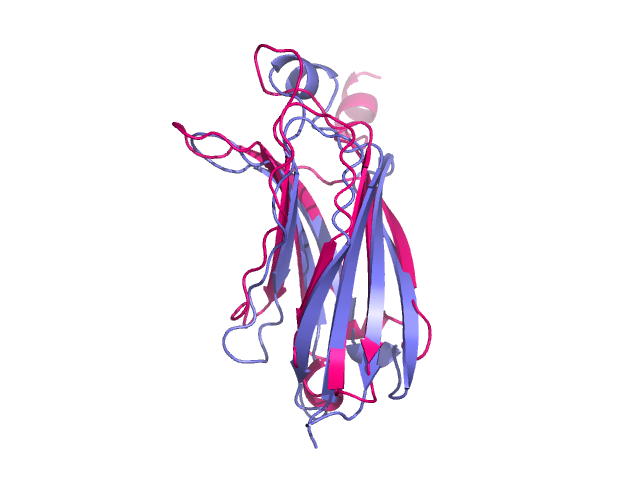
Two proteins after structure alignment


Algorithm Details
align does a BLAST-like BLOSUM62-weighted dynamic programming sequence alignment followed by a series of refinement cycles intended to improve the fit by eliminating pairing with high relative variability (e.g. >2 standard deviations from the cycle's mean deviance).
Your can write the final alignment to a file see save.
Super!
PyMOL now has another command -- super. Super allows for much more robust alignments. It's fast, and under testing, does MUCH better than the original align command.
USAGE
align (source), (target) [,cutoff [,cycles [,gap [,extend \
[,skip [,object [,matrix [, quiet ]]]]]]]]
PYMOL API
cmd.align( string mobile, string target, float cutoff=2.0,
int cycles=5, float gap=-10.0, float extend=-0.5,
int max_gap=50, string object=None, string matrix='BLOSUM62',
int mobile_state=0, int target_state=0, int quiet=1,
int max_skip=0, int transform=1, int reset=0 )
This returns a list with 7 items:
- RMSD after refinement
- Number of aligned atoms after refinement
- Number of refinement cycles
- RMSD before refinement
- Number of aligned atoms before refinement
- Raw alignment score
- Number of residues aligned
EXAMPLES
align prot1////CA, prot2, object=alignment
NOTE
- If object is not None, then align will create an object which indicates which atoms were paired between the two structures
- Important note: the molecules you want to align need to be in two different objects. Else, PyMol will answer with a rather cryptic error:
ExecutiveAlign: invalid selections for alignment.
You can skirt this problem by making a temporary object and aligning your original to the copy.
- Sometimes Align may appear to give a mediocre fit. This is not due to any shortcoming of the algorithm or Pymol for that matter. This usually happens if one or more of the objects, that you are trying to align, have multiple states. For instance, certain PDB files may contain multiple structures/ensembles of the same protein. This is especially true for PDB files containing NMR structures. The workaround in such a situation is to use this workflow (provided by Warren - thanks!):
set all_states, on
intra_fit <your_structure_1>
intra_fit <your_structure_2>
align <your_structure_1>////CA, <your_structure_2>////CA
SEE ALSO
fit, rms, rms_cur, intra_rms, intra_rms_cur, pair_fit, intra_fit, Kabsch, Cealign, Color_by_conservation, tmalign, Extra_fit, align_all.py and super_all.py.